大字段如何对查询产生影响
2021-10-10 16:10:31 1008
一些应用, 在表结构的设计上使用了text或者blob的字段;其中一个应用,对blob/text字段的依赖非常的严重,查询和更新的频率也是非常的高,单表的存储空间已经达到了近100G,这个时候,应用其实已经被数据库绑死了,任何应用或者查询逻辑的变更几乎成为不可能;
为了清楚大字段对性能的影响,我们必须要知道innodb存储引擎在底层对行的处理方式:
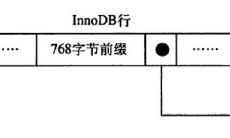
在5.1中,innodb存储引擎的默认的行格式为compact(redundant为兼容以前的版本),对于blob,text,varchar(8099)这样的大字段,innodb只会存放前768字节在数据页中,而剩余的数据则会存储在溢出段中(发生溢出情况的时候适用);

innodb的块大小默认为16kb,由于innodb存储引擎表为索引组织表,树底层的叶子节点为一双向链表,因此每个页中至少应该有两行记录,这就决定了innodb在存储一行数据的时候不能够超过8k(8098字节);
使用了blob数据类型,是不是一定就会存放在溢出段中?通常我们认为blob,clob这类的大对象的存储会把数据存放在数据页之外,其实不然,关键点还是要看一个page中到底能否存放两行数据,blob可以完全存放在数据页中(单行长度没有超过8098字节),而varchar类型的也有可能存放在溢出页中(单行长度超过8098字节,前768字节存放在数据页中); 5.1中的innodb_plugin引入了新的文件格式:barracuda(将compact和redundant合称为antelope),该文件格式拥有新的两种行格式:compressed和dynamic,两种格式对blob字段采用完全溢出的方式,数据页中只存放20字节,其余的都存放在溢出段中:

mysql在操作数据的时候,以page为单位,不管是更新,插入,删除一行数据,都需要将那行数据所在的page读到内存中,然后在进行操作,这样就存在一个命中率的问题,如果一个page中能够相对的存放足够多的行,那么命中率就会相对高一些,性能就会有提升; 有了上面的知识点,我们一起看看该应用的特点,表结构:
CREATE TABLE `xx_msg` (
`col_user` VARCHAR(64) NOT NULL,
`col_smallint` SMALLINT(6) NOT NULL,
`col_lob` longblob,
`gmt_create` datetime DEFAULT NULL,
`gmt_modified` datetime DEFAULT NULL,
PRIMARY KEY (`xxx`)
) ENGINE=InnoDB DEFAULT CHARSET=gbkcol_lob为blob字段,用于存放该用户的所有的消息,其平均长度在2.4kb左右,该表中其他剩余的字段则是非常的小,大致在60字节左右
SELECT avg(LENGTH(col_clob)) FROM (SELECT * fromxxx_msg LIMIT 30000)a;
| 2473.8472 |该表的应用场景包括:
- select col_user ,col_smallint,DATE_FORMAT(gmt_modified,’%Y-%m-%d’) from xx_msg;
- update xx_msg set gmt_modified=’2012-03-31 23:16:30′,col_smallint=1,col_lob=’xxx’ where col_user=’xxx’;
- select col_smallint from xx_msg where user=’xxx’;
可以看到由于单行的平均长度(2.5k)还远小于一个innodb page的size(16k)(当然也有存在超过8k的行),也就是知识点三中提到的,blob并不会存放到溢出段中,而是存放到数据段中去,innodb能够将一行的所有列(包括longlob)存储在数据页中:
 在知识点五中,mysql的io以page为单位,因此不必要的数据(大字段)也会随着需要操作的数据一同被读取到内存中来,这样带来的问题由于大字段会占用较大的内存(相比其他小字段),使得内存利用率较差,造成更多的随机读取。
在知识点五中,mysql的io以page为单位,因此不必要的数据(大字段)也会随着需要操作的数据一同被读取到内存中来,这样带来的问题由于大字段会占用较大的内存(相比其他小字段),使得内存利用率较差,造成更多的随机读取。
从上面的分析来看,我们已经看到性能的瓶颈在于由于大字段存放在数据页中,造成了内存利用较差,带来过多的随机读,那怎么来优化掉这个大字段的影响:
一. 压缩:
在知识点四中,innodb提供了barracuda文件格式,将大字段完全存放在溢出段中,数据段中只存放20个字节,这样就大大的减小了数据页的空间占用,使得一个数据页能够存放更多的数据行,也就提高了内存的命中率(对于本实例,大多数行的长度并没有超过8k,所以优化的幅度有限);如果对溢出段的数据进行压缩,那么在空间使用上也会大大的降低,具体的的压缩比率可以设置key_blok_size来实现。
二. 拆分:
将主表拆分为一对一的两个关联表:
CREATE TABLE `xx_msg` (
`col_user` VARCHAR(64) NOT NULL,
`col_smallint` SMALLINT(6) NOT NULL,
`gmt_create` datetime DEFAULT NULL,
`gmt_modified` datetime DEFAULT NULL,
PRIMARY KEY (`xxx`)
) ENGINE=InnoDB DEFAULT CHARSET=gbk;
CREATE TABLE `xx_msg_lob` (
`col_user` VARCHAR(64) NOT NULL,
`col_lob` longblob,
PRIMARY KEY (`xxx`)
) ENGINE=InnoDB DEFAULT CHARSET=gbk
xx_msg表由于将大字段单独放到另外一张表后,单行长度变的非常的小,page的行密度相比原来的表大很多,这样就能够缓存足够多的行,表上的多个select由于buffer pool的高命中率而受益;应用程序需要额外维护的是一张大字段的子表;
三.覆盖索引:
在上面的两个查询当中,都是查询表中的小字段,由于老的方案需要全表或者根据主键来定位表中的数据,但是还是以page为单位进行操作,blob字段存在还是会导致buffer pool命中率的下降,如果通过覆盖索引来优化上面的两个查询,索引和原表结构分开,从访问密度较小的数据页改为访问密度很大的索引页,随机io转换为顺序io,同时内存命中率大大提升;额外的开销为数据库多维护一个索引的代价;
alter table xx_msg add index ind_msg(col_user ,col_smallint,gmt_modified);对于查询一,原来的执行计划为走全表扫描,现在通过全索引扫描来完成查询;
对于查询二,原来的执行计划为走主键PK来定位数据,现在该走覆盖索引ind_msg完成查询;
注意上面的两个查询为了稳固执行计划,需要在sql执行中加入hint提示符来强制sql通过索引来完成查询;
总结:上面三种思路来优化大字段,其核心思想还是让单个page能够存放足够多的行,不断的提示内存的命中率,尽管方法不同,但条条大路通罗马,从数据库底层存储的原理出发,能够更深刻的优化数据库,扬长避短,达到意想不到的效果。