窗口函数
2025-09-09 19:48:30 51
SQL 查询的一般逻辑执行顺序
- FROM:先加载数据源(表或视图),包括任何 JOIN。
- WHERE:对行进行筛选。
- GROUP BY:对行进行分组(如果有聚合)。
- HAVING:对分组结果筛选。
- SELECT:选择列、计算表达式,同时处理窗口函数。
- WINDOW FUNCTIONS(OVER 子句):窗口函数在 SELECT 阶段计算,它可以看到当前行及“窗口帧”内的其他行。
- DISTINCT:去重(如果有)。
- ORDER BY:排序。
- LIMIT / OFFSET:返回最终结果
可以看到窗口函数是在SELECT阶段执行的, 近似看作最终结果集
什么是窗口
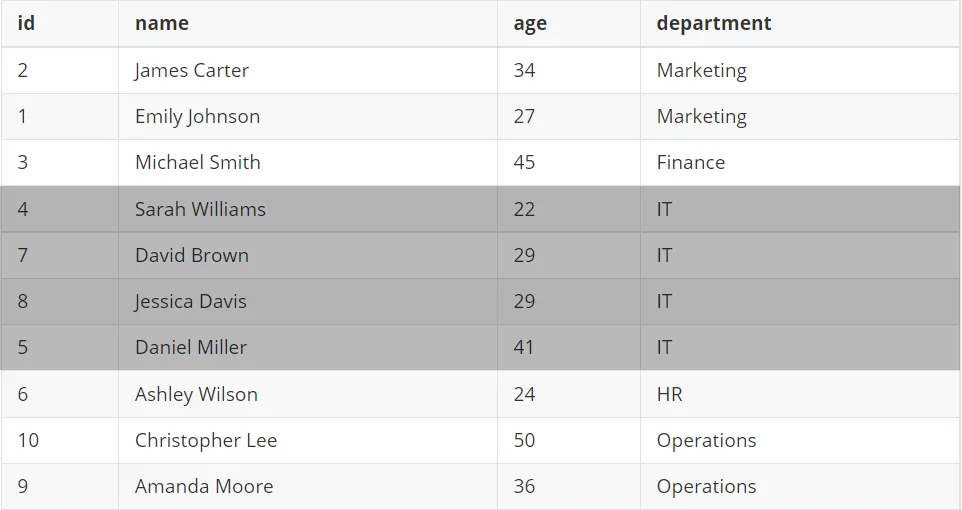
如图, 10条SELECT出的数据, 根据分区规则 (department), 同样部门的人视为窗口, 在窗口内的每一行数据, 都能看到窗口范围内的数据. 比如id为4/7/8/5的行, 都能看黑色范围内的数据.
如果定义了排序规则, 则数据还会进行窗口内的排序
语法定义如下
OVER (
[PARTITION BY partition_expression, ... ]
[ORDER BY sort_expression [ASC | DESC], ...]
[ROWS frame_specification]
-- or
[RANGE frame_specification]
)
UNBOUNDED PRECEDING:窗口从当前分区的第一行开始。
N PRECEDING:窗口从当前行之前的第N行开始,N是一个正整数。
CURRENT ROW:窗口从当前行开始。
N FOLLOWING:窗口从当前行之后的第N行开始。
UNBOUNDED FOLLOWING:窗口到当前分区的最后一行结束(通常只用于frame_end)。窗口函数的执行步骤可以这样理解:
- 分区(PARTITION BY)如果有 PARTITION BY,就先把整个结果集按照这个字段分区,每一行只看自己分区内的数据。
- 排序(ORDER BY)如果有 ORDER BY,就对分区内的数据排序,这影响累计函数、排名函数等的结果。
- 计算窗口帧(frame)默认窗口帧是:
- 没有 ORDER BY:整个分区。
- 有 ORDER BY:从分区开始到当前行(
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)。 - 执行函数对窗口帧里的数据执行函数计算,比如:
ROW_NUMBER()→ 给分区内每行生成序号SUM(salary) OVER(PARTITION BY dept ORDER BY salary)→ 计算累积和AVG(salary) OVER(PARTITION BY dept)→ 计算分区平均
关于ROWS和RANGE的区别
●ROWS → 多少行
●RANGE → 值在多大区间
比如上图, 在 IT 分区内如果根据age排序后
ROWS
select
name,
age,
department,
avg(age) over (partition by department
order by age
rows between 1 preceding and 1 following) as avg_age
from
employees
|name |age|department|avg_age |
|---------------|---|----------|-------------|
|Michael Smith |45 |Finance |45 |
|Ashley Wilson |24 |HR |24 |
|Sarah Williams |22 |IT |25.5 |
|David Brown |29 |IT |26.6666666667|
|Jessica Davis |29 |IT |33 |
|Daniel Miller |41 |IT |35 |
|Emily Johnson |27 |Marketing |30.5 |
|James Carter |34 |Marketing |30.5 |
|Amanda Moore |36 |Operations|43 |
|Christopher Lee|50 |Operations|43 |窗口范围 = 当前行的前一行 + 当前行 + 当前行的后一行
Jessica Davis这行, 可以看到David Brown和Daniel Miller的数据, (29+29+41)/3=33
RANGE
select
name,
age,
department,
avg(age) over (partition by department
order by age
range between 7 preceding and 12 following) as avg_age
from
employees
|name |age|department|avg_age |
|---------------|---|----------|-------------|
|Michael Smith |45 |Finance |45 |
|Ashley Wilson |24 |HR |24 |
|Sarah Williams |22 |IT |26.6666666667|
|David Brown |29 |IT |30.25 |
|Jessica Davis |29 |IT |30.25 |
|Daniel Miller |41 |IT |41 |
|Emily Johnson |27 |Marketing |30.5 |
|James Carter |34 |Marketing |30.5 |
|Amanda Moore |36 |Operations|36 |
|Christopher Lee|50 |Operations|50 |窗口范围 = 当前行的值 - 7 到当前行的值 +12 之间的所有行
Sarah Williams: (22+29+29) / 3 = 26.6666666667
David Brown/Jessica Davis: (22+29+29+41) / 4 = 30.25
Daniel Miller: 之前和之后都没有数据, 所以仍是41
1. 排名类
| 函数 | 说明 | 特点 |
| ROW_NUMBER() | 为分区内的每一行分配唯一递增编号(从 1 开始)。 | 不考虑重复值,每行编号都不同。 |
| RANK() | 为分区内的行排名,相同值排名相同,下一名会跳号。 | 有“并列”。例:1,2,2,4。 |
| DENSE_RANK() | 类似 RANK,但不会跳号。 | 有“并列”。例:1,2,2,3。 |
| NTILE(n) | 将分区内的行尽量平均分为 n 组,并返回组号。 | 常用于分位数计算。 |
2. 聚合类(与普通聚合类似,但不减少行数)
| 函数 | 说明 | 特点 |
| SUM(expr) | 计算窗口内的总和。 | 窗口范围由 ROWS/RANGE 控制。且受ORDER BY影响 |
| AVG(expr) | 计算窗口内的平均值。 | |
| COUNT(expr) | 统计窗口内的行数。 | |
| MIN(expr) / MAX(expr) | 窗口内的最小值 / 最大值。 |
3. 分析类
| 函数 | 说明 | 特点 |
| LAG(expr, offset, default) | 返回当前行之前第 offset 行的值。 | 常用于对比前一行。 |
| LEAD(expr, offset, default) | 返回当前行之后第 offset 行的值。 | 常用于对比后一行。 |
| FIRST_VALUE(expr) | 返回窗口内排序后第一行的值。 | |
| LAST_VALUE(expr) | 返回窗口内排序后最后一行的值。 | |
| NTH_VALUE(expr, n) | 返回窗口内第 n 行的值。 |
示例
1. 查询每个人的年龄与部门平均年龄的差值
select
name,
age,
department,
avg(age) over (partition by department) - age as age_value
from
employees
|name |age|department|age_value|
|---------------|---|----------|---------|
|Michael Smith |45 |Finance |0 |
|Ashley Wilson |24 |HR |0 |
|Jessica Davis |29 |IT |1.25 |
|Daniel Miller |41 |IT |-10.75 |
|David Brown |29 |IT |1.25 |
|Sarah Williams |22 |IT |8.25 |
|Emily Johnson |27 |Marketing |3.5 |
|James Carter |34 |Marketing |-3.5 |
|Christopher Lee|50 |Operations|-7 |
|Amanda Moore |36 |Operations|7 |2. 给各部门的人按年龄排序
select
name,
age,
department,
rank() over (partition by department order by age) sort
from
employees
|name |age|department|sort|
|---------------|---|----------|----|
|Michael Smith |45 |Finance |1 |
|Ashley Wilson |24 |HR |1 |
|Sarah Williams |22 |IT |1 |
|David Brown |29 |IT |2 |
|Jessica Davis |29 |IT |2 |
|Daniel Miller |41 |IT |4 |
|Emily Johnson |27 |Marketing |1 |
|James Carter |34 |Marketing |2 |
|Amanda Moore |36 |Operations|1 |
|Christopher Lee|50 |Operations|2 |附
CREATE TABLE public.employees (
id int4 NOT NULL,
"name" varchar(100) NOT NULL,
age int4 NULL,
department varchar(50) NOT NULL,
CONSTRAINT employees_pkey PRIMARY KEY (id)
);
INSERT INTO public.employees (id,"name",age,department) VALUES
(2,'James Carter',34,'Marketing'),
(1,'Emily Johnson',27,'Marketing'),
(3,'Michael Smith',45,'Finance'),
(4,'Sarah Williams',22,'IT'),
(8,'Jessica Davis',29,'IT'),
(5,'Daniel Miller',41,'IT'),
(6,'Ashley Wilson',24,'HR'),
(10,'Christopher Lee',50,'Operations'),
(9,'Amanda Moore',36,'Operations'),
(7,'David Brown',29,'IT');